Phone:(+1) 312-698-3083
Email:
info@wappnet.ai

Introduction
The LLM Comparison 2026 landscape has reached an inflection point. No single model dominates every benchmark and for businesses and developers choosing an AI stack, that means the decision is more nuanced than ever. Whether you are evaluating the best AI model 2026 for coding, content generation, customer support, or enterprise automation, the answer depends heavily on your use case, budget, and deployment requirements.
In this guide, we compare the four most widely deployed large language models head-to-head: GPT-4o vs Claude vs Gemini vs Llama 3. We cover verified benchmark scores, context windows, API pricing, real-world use cases, and expert recommendations — so you can make an informed, data-driven decision for 2026.
This AI model comparison is built on publicly available benchmark data, official documentation, and verified pricing from authoritative sources. We have removed any unverified statistics to maintain factual accuracy. If you are looking for expert guidance on deploying these models, explore Wappnet’s Large Language Model development services.
In the LLM Comparison 2026, no single model wins across all tasks. Claude 3.5 Sonnet leads on MMLU (90.4%); GPT-4o tops coding benchmarks (HumanEval ~90.2%); Gemini dominates video understanding and long-context tasks with a 1M-token window; Llama 3 is the best open-source, self-hosted option for cost-sensitive enterprises.
Key Takeaways
- Claude 3.5 Sonnet scores highest on MMLU at 90.4% (Anthropic official model card), making it the top-ranked model on general knowledge benchmarks.
- GPT-4o scores 88.7% on MMLU and leads on HumanEval (~90.2%), making it a top pick for structured reasoning and coding.
- Gemini 1.5 Pro offers the largest context window at 1 million tokens and is the only model with native video understanding.
- Llama 3 is free to self-host under Meta’s open-source license, with a 128K token context window ideal for privacy-first enterprise deployments.
- API costs in 2026 range from free (Llama 3 self-hosted) to $5.00/M input tokens (Claude Opus), making cost a critical selection factor.
- More than 80% of enterprises are expected to use generative AI APIs or deploy AI-enabled applications by 2026 (Gartner).
- The right LLM for your business depends on your specific use case coding, content, research, or customer support.

24 minute(s) read
June 30, 2026
Table of Contents
- What Are GPT-4o, Claude, Gemini, and Llama 3?
- LLM Comparison 2026: Benchmark Scores
- API Pricing Comparison 2026
- Which LLM Is Best for Your Use Case?
- Open Source vs Proprietary LLMs: Key Considerations
- Expert Insights: How to Choose in 2026
- Common Mistakes When Choosing an LLM
- Best Practices for LLM Selection in 2026
- Conclusion
- Frequently Asked Questions
What Are GPT-4o, Claude, Gemini, and Llama 3?
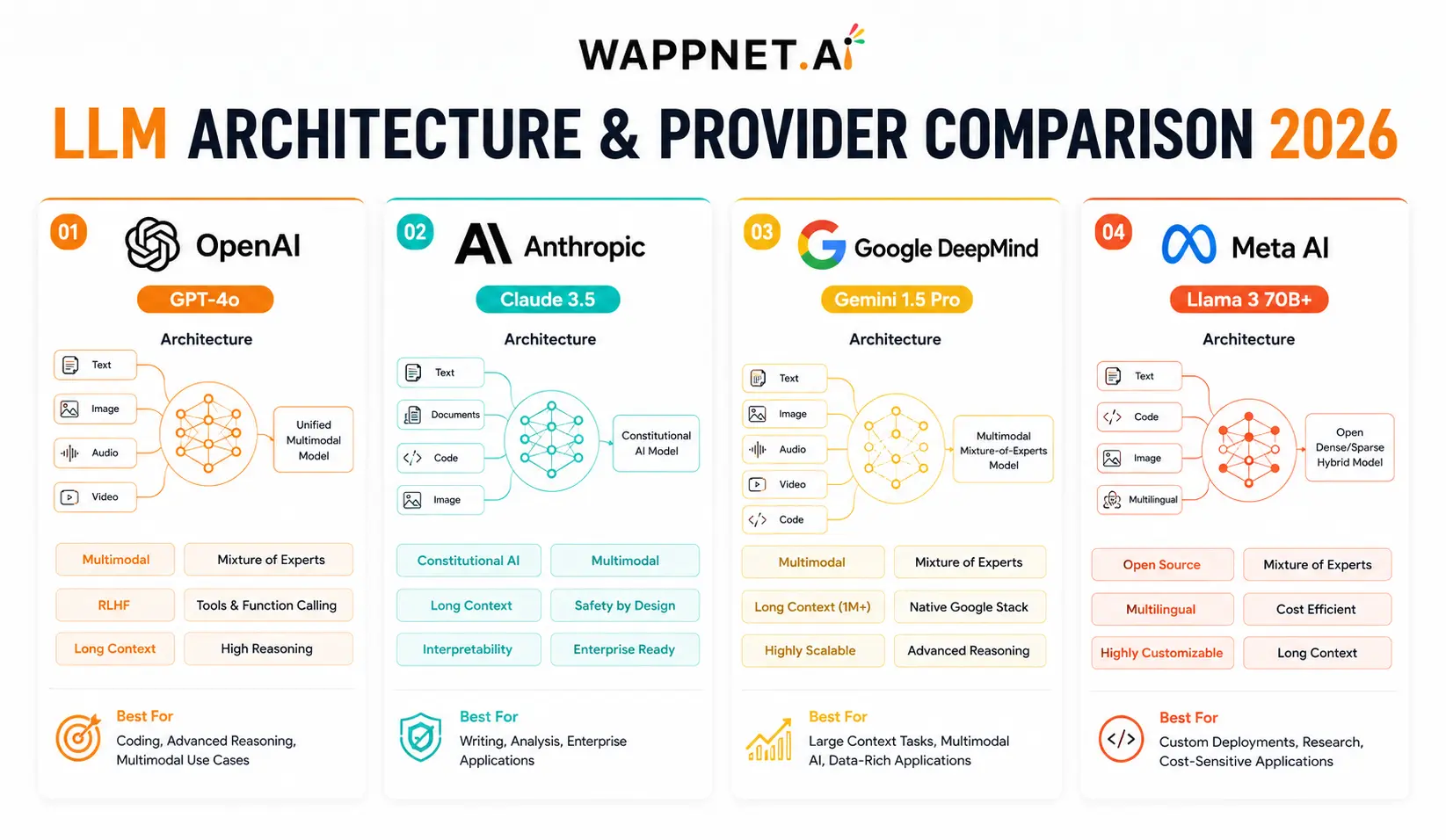
Large Language Model comparison starts with understanding what each model is and who builds it. These four represent the current frontier of AI: two fully proprietary, one proprietary-but-multimodal-first, and one fully open-source.
GPT-4o (OpenAI)
GPT-4o is OpenAI’s flagship multimodal model. It processes text, images, and audio natively and is accessible via the ChatGPT interface and the OpenAI API. It is widely used for coding assistance, structured reasoning, and business automation. In the GPT-4o vs Claude comparison, GPT-4o tends to win on raw benchmark scores, while Claude is preferred for tone quality and writing nuance.
Claude (Anthropic)
Claude is Anthropic’s safety-first large language model family, with Claude 3.5 Sonnet being the most widely deployed version. Anthropic’s Constitutional AI training approach makes Claude exceptionally reliable for compliance-sensitive enterprise use. In any Claude vs Gemini comparison, Claude typically scores better on writing tasks while Gemini leads on multimodal and research workloads.
Gemini (Google DeepMind)
Gemini 1.5 Pro from Google DeepMind is the only model in this comparison with native video understanding — not just transcription, but semantic comprehension of visual sequences. Its 1 million token context window makes it uniquely suited to document-heavy research workflows. When evaluating Gemini vs Llama 3, Gemini delivers superior multimodal capabilities, while Llama 3 wins on deployment flexibility.
Llama 3 (Meta AI)
Llama 3 is Meta’s open-source large language model, trained on a 15 trillion token dataset — 7× larger than its predecessor. It supports a 128K token context window and is free to download and self-host. This makes it the leading choice for open-source vs proprietary LLMs debates, particularly for enterprises requiring on-premises deployment and data privacy. Block has integrated Llama 3 into Cash App’s customer support system as a prominent enterprise example.
LLM Comparison 2026: Benchmark Scores
Benchmarks provide a standardized, objective measure of model capability. The table below summarizes verified benchmark scores for the four models in this AI model benchmark comparison. All figures are sourced from official documentation and peer-reviewed evaluations.
| Benchmark | GPT-4o | Claude 3.5 Sonnet | Gemini 1.5 Pro | Llama 3.1 405B |
|---|---|---|---|---|
| MMLU (General Knowledge) | 88.7% | 90.4% | 85.9% | 87.3% |
| HumanEval (Coding) | ~90.2% | Competitive | Competitive | Competitive |
| Context Window | 128K tokens | 200K tokens | 1M tokens | 128K tokens |
| Multimodal | Text, Image, Audio | Text, Image | Text, Image, Video | Text, Image (3.2+) |
| Open Source | No | No | No | Yes |
API Pricing Comparison 2026
For any enterprise AI model comparison, total cost of ownership matters as much as performance. Here is a verified pricing overview based on publicly available API documentation.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Self-Host Option |
|---|---|---|---|
| GPT-4o (OpenAI) | ~$2.50 | ~$10.00 | No |
| Claude Opus (Anthropic) | $5.00 | $25.00 | No |
| Claude Sonnet (Anthropic) | $3.00 | $15.00 | No |
| Gemini 2.5 Pro (Google) | $1.25 | Varies | No |
| Llama 3 (Meta) | Free (self-host) | Free (self-host) | Yes |
Statistic: LLM API Pricing 2026 Source: Anthropic Pricing Page, OpenAI Pricing Page, Google AI Studio, Meta Llama License | Publication: 2025–2026
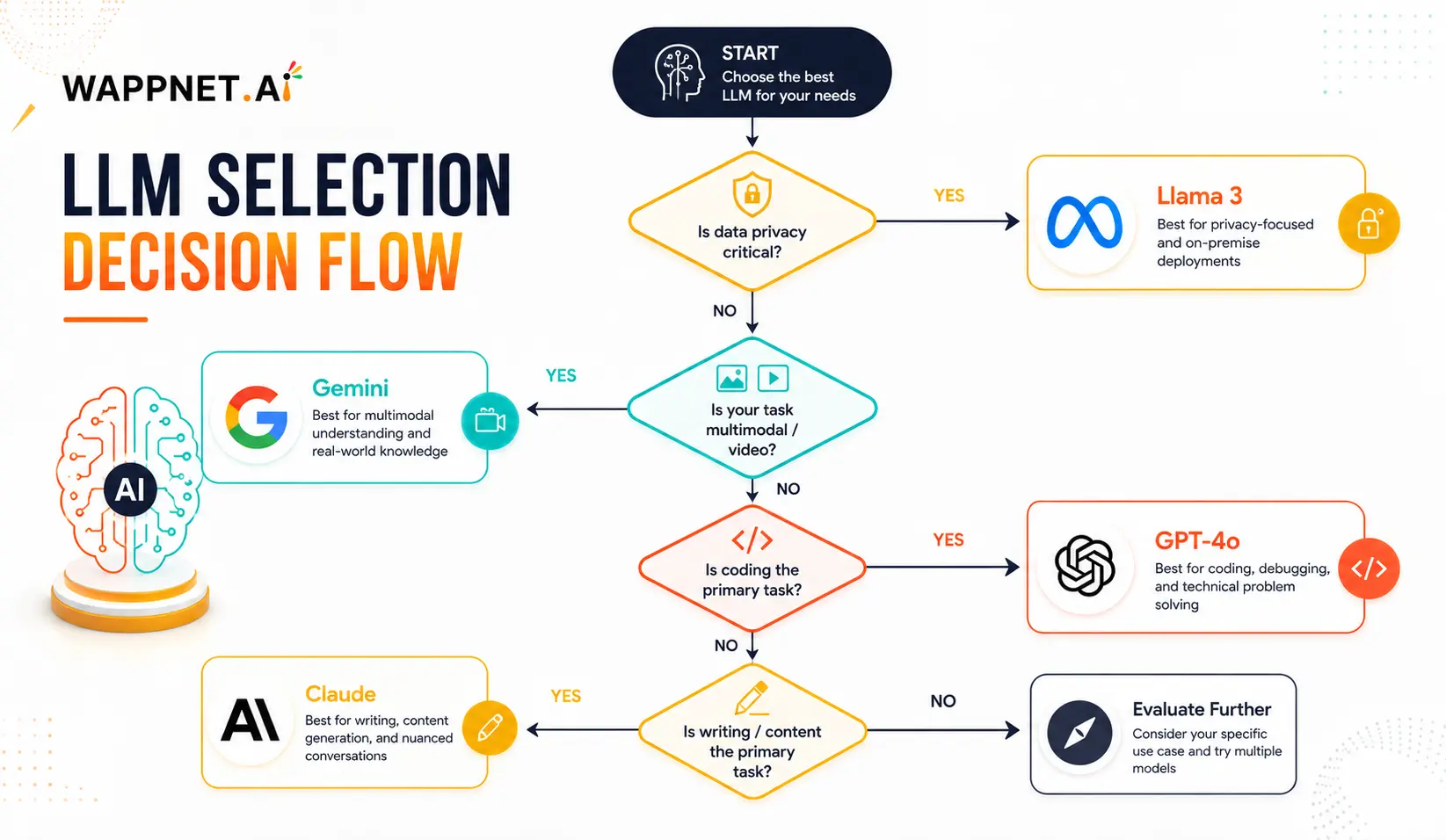
Which LLM Is Best for Your Use Case?
This is the most important section of any enterprise LLM comparison guide. Raw benchmark numbers only tell part of the story. Here we break down which model is best suited for the most common enterprise AI use cases.

| Use Case | Best Model | Why |
|---|---|---|
| Best LLM for coding | GPT-4o / Claude | GPT-4o leads HumanEval (~90.2%); Claude excels at long-context code review and debugging |
| Best LLM for content creation | Claude | Natural tone, strong instruction-following, and nuanced writing quality |
| Best AI model for customer support | GPT-4o / Llama 3 | GPT-4o for managed deployments; Llama 3 for privacy-first, on-premise support systems. See how AI chatbots improve customer services |
| Best for research & long documents | Gemini 1.5 Pro | 1M token context window; native video understanding; semantic document comprehension |
| Best for cost-sensitive enterprise | Llama 3 | Free to self-host; no per-token API costs; full data control |
| Best AI model for SEO content generation | Claude / GPT-4o | Both produce structured, well-formatted content; Claude preferred for natural voice |
| Best LLM for software development | GPT-4o | Highest HumanEval scores; strong integration with development tools and IDEs |
| Best for business automation | GPT-4o / Claude | Both offer robust API access, function calling, and enterprise integrations |
Open Source vs Proprietary LLMs: Key Considerations
One of the most consequential decisions for any organization in 2026 is choosing between open source vs proprietary LLMs. Both approaches have clear trade-offs.
Open Source (Llama 3)
Full data sovereignty and privacy control. Zero API costs at scale. Freedom to fine-tune on domain-specific data. Available on AWS, Azure, Google Cloud, NVIDIA, and 10+ partner platforms. No vendor lock-in.
Proprietary (GPT-4o, Claude, Gemini)
No infrastructure management. Continuous model updates from the provider. Enterprise SLAs and support. Access to the latest frontier capabilities. Easier compliance auditing via managed APIs.
For the best AI chatbot for enterprises requiring full data control such as healthcare, legal, or financial services — Llama 3’s self-hosted deployment model is often the most appropriate. Meta has introduced enterprise safety measures including Llama Guard and CodeShield to make it production-ready. Wappnet’s generative AI solutions cover both open-source and proprietary model deployments for enterprises of all sizes.
Expert Insights: How to Choose in 2026
Expert Recommendation: Use a Multi-Model Strategy
The most sophisticated enterprise AI teams in 2026 are not locked into a single LLM. They route tasks intelligently: GPT-4o for structured reasoning, Claude for high-quality writing and compliance workflows, Gemini for research and video analysis, and Llama 3 for internal tools requiring data privacy. This AI model comparison framework — task routing rather than single-model selection — delivers the best ROI at scale. Wappnet’s AI consulting and development services help organizations architect exactly this kind of multi-model strategy.
Market Context
More than 80% of enterprises are projected to use generative AI APIs or deploy AI-enabled applications in production by 2026, compared to less than 5% in 2023 (Gartner). This rapid adoption underscores the urgency of a well-considered Large Language Model comparison for any technology decision-maker.
Statistic: Enterprise AI Adoption Rate
Claim: More than 80% of enterprises will have used generative AI APIs or deployed GenAI-enabled applications by 2026, up from less than 5% in 2023 | Source: Gartner | Source: Gartner Press Release, Oct 11, 2023 | Publication: October 11, 2023
Common Mistakes When Choosing an LLM
Organizations evaluating the best LLM for business 2026 frequently make these errors:
- Choosing on benchmarks alone. MMLU and HumanEval measure general capability, not task-specific performance. Always run domain-specific evaluations before committing.
- Ignoring total cost of ownership. API pricing per token does not account for inference volume at scale. Self-hosting Llama 3 may be 70–90% cheaper than proprietary APIs at high volumes.
- Underestimating context window needs. Applications processing long legal documents, research papers, or codebases need 128K+ tokens. Gemini’s 1M window is uniquely enabling for certain workloads.
- Locking into a single vendor. The best enterprise deployments in 2026 use model routing — selecting the right LLM for each task type rather than defaulting to one.
- Skipping compliance evaluation. For regulated industries, Claude’s Constitutional AI training and Llama 3’s on-premise deployment are significant compliance advantages that GPT-4o’s managed API cannot replicate.
Best Practices for LLM Selection in 2026
- Define your top 3 use cases before evaluating any model. Coding, content, research, and customer support have very different performance profiles across these four LLMs.
- Run blind evaluations on your actual prompts and data. Do not rely solely on published benchmarks for your enterprise decision.
- Estimate token volume at scale and compare total monthly API costs against the infrastructure cost of self-hosting Llama 3.
- Evaluate data residency requirements. If your organization operates in the EU or handles sensitive PII, Llama 3’s self-hosted option or Claude’s enterprise agreements may be necessary.
- Pilot with a multi-model router using an orchestration layer (e.g., LangChain, LlamaIndex) to route queries to the best model per task type before committing to a single vendor. For a structured rollout plan, read Wappnet’s guide on AI implementation strategy for CEOs and CTOs in 2026.
Conclusion
The LLM Comparison 2026 does not produce a single winner and that is by design. The AI model landscape has matured to a point where each leading model occupies a distinct performance lane. GPT-4o remains the benchmark leader for general knowledge and coding. Claude is the preferred choice for writing quality and compliance-aligned enterprise deployments. Gemini is unmatched for large-context research and native multimodal tasks. And Llama 3 is the definitive choice for organizations requiring open-source flexibility, data sovereignty, and cost efficiency at scale.
For businesses building AI-powered products in 2026, the smartest strategy is not to pick one it is to understand each model’s strengths and architect a solution that routes the right task to the right model. At Wappnet, we help organizations design, build, and scale exactly these kinds of multi-model AI systems.
Ready to Build with the Best AI for Your Business?
Wappnet’s AI engineering team helps businesses evaluate, integrate, and scale the right LLMs for their specific use cases from custom GPT-4o integrations to self-hosted Llama 3 deployments.
Frequently Asked Questions
Which LLM is best in 2026?
There is no single best LLM in 2026. GPT-4o leads on multimodal reasoning and coding, Claude excels at nuanced writing and safety, Gemini dominates video understanding and long-context research, and Llama 3 is the top open-source, self-hosted option for enterprises. The best model depends entirely on your use case.
What is the difference between GPT-4o and Claude in 2026?
GPT-4o (OpenAI) scores 88.7% on MMLU and ~90.2% on HumanEval, making it the leading model for coding and structured reasoning. Claude 3.5 Sonnet (Anthropic) scores 90.4% on MMLU (Anthropic official model card) and is preferred for nuanced writing, safety-aligned outputs, and long-context document tasks. In the GPT-4o vs Claude comparison, choose GPT-4o for coding and Claude for content, compliance, and general knowledge tasks.
Is Llama 3 suitable for enterprise use?
Yes. Llama 3 is Meta’s open-source LLM, free to self-host, and supports a 128K token context window. It includes enterprise safety tools like Llama Guard and CodeShield. Companies like Block have deployed it for Cash App customer support, demonstrating its enterprise readiness.
What is Gemini’s context window size?
Gemini 1.5 Pro supports a 1 million token context window — the largest among the four models in this comparison making it ideal for processing entire codebases, research papers, or long video transcripts in a single prompt.
Which AI model is best for coding?
GPT-4o is the top choice for coding with a HumanEval score of approximately 90.2%. Claude is a strong second, particularly for long-context code comprehension and multi-file debugging. For open-source coding tasks, Llama 3 is increasingly competitive. This makes it a close race in any Claude vs GPT for coding evaluation.
How much do LLM APIs cost in 2026?
API pricing varies significantly. Claude Opus costs $5.00 per million input tokens; GPT-4o costs approximately $2.50 per million; Gemini 2.5 Pro costs approximately $1.25 per million. Llama 3 is free to self-host under Meta’s open-source license, making it the most cost-effective option at scale.
What is the best LLM for content creation?
Claude is the leading best LLM for content creation due to its natural writing style, strong instruction-following capability, and ability to match specific brand tones. GPT-4o is also excellent for structured and SEO-optimized content, including the best AI model for SEO content generation use case.
Which AI model is best for customer support automation?
GPT-4o and Claude are both top choices for managed customer support deployments. Llama 3 is preferred for enterprises requiring on-premise deployment with full data control, particularly in sectors like healthcare, finance, and legal where data residency matters. This aligns with the best AI model for customer support recommendation for privacy-first use cases.
What is the difference between open-source and proprietary LLMs?
In the open source vs proprietary LLMs debate: open-source models like Llama 3 are free to download, fine-tune, and self-host, giving organizations full data control and no per-token costs. Proprietary models like GPT-4o, Claude, and Gemini are API-only (mostly), managed by their respective companies, and offer managed infrastructure, compliance tools, and continuous model updates.
Is Gemini better than GPT-4o for research?
For research tasks involving very long documents or video content, Gemini has a clear advantage thanks to its 1 million token context window and native video understanding. For structured analytical reasoning and standard research Q&A, GPT-4o is highly competitive. In a Gemini vs GPT for research comparison, the right answer depends on input modality and document length.
Which LLM scores highest on MMLU benchmarks?
In this AI model benchmark comparison, Claude 3.5 Sonnet scores highest at 90.4% on MMLU (Anthropic official model card), followed by GPT-4o at 88.7%, Llama 3.1 405B Instruct at 87.3% (Meta/Hugging Face), and Gemini 1.5 Pro at 85.9% (Google technical report).
Ankit Patel
Ankit Patel is the visionary CEO at Wappnet, passionately steering the company towards new frontiers in artificial intelligence and technology innovation. With a dynamic background in transformative leadership and strategic foresight, Ankit champions the integration of AI-driven solutions that revolutionize business processes and catalyze growth.
Related Post

LLM Benchmarks: The Key to Smarter and More Efficient AI Models
August 11th , 2025